
Conceptos

La IA (Inteligencia Artificial) es una rama de la informática que busca crear máquinas o programas capaces de realizar tareas que normalmente requieren inteligencia humana.
Estas tareas incluyen cosas como:
-
Reconocimiento de voz o imágenes (por ejemplo, cuando tu teléfono entiende lo que dices).
-
Toma de decisiones (como los sistemas que recomiendan películas o rutas de viaje).
-
Aprendizaje automático (machine learning), donde las máquinas aprenden de los datos sin ser programadas explícitamente para cada tarea.
-
Procesamiento del lenguaje natural, que permite a los sistemas entender y responder en lenguaje humano (como yo 😊).
En resumen, la IA trata de imitar la forma en que las personas piensan, aprenden y resuelven problemas, pero usando algoritmos y datos.
Arquitectura
┌───────────────────────────────────────────────────────────────┐
│ USUARIO │
│───────────────────────────────────────────────────────────────│
│ 💬 Usa navegador web (Chrome, Firefox, etc.) │
│ 🌐 Accede a http://tu-servidor:3000 │
└───────────────┬───────────────────────────────────────────────┘
│ 1️⃣ Escribe / envía prompt
▼
┌──────────────────────────────────────────────────────────────────────┐
│ 🖥️ Open WebUI (contenedor Docker) │
│──────────────────────────────────────────────────────────────────────│
│ - Interfaz tipo ChatGPT │
│ - Guarda historiales de chat (persistencia) │
│ - Tiene “Knowledge Base” (memoria larga / aprendizaje) │
│ - Llama al modelo LLM a través de API local │
└───────────────┬──────────────────────────────────────────────────────┘
│ 2️⃣ Envía prompt al motor de IA local (Ollama)
▼
┌──────────────────────────────────────────────────────────────────────┐
│ 🧠 Ollama (host, fuera del contenedor) │
│──────────────────────────────────────────────────────────────────────│
│ - Maneja modelos LLM (Llama 3, Mistral, Phi-3, etc.) │
│ - Usa GPU vía CUDA para acelerar inferencia │
│ - Expone API local http://localhost:11434 │
│ - Compatible con múltiples modelos y embeddings │
└───────────────┬──────────────────────────────────────────────────────┘
│ 3️⃣ Llama a la GPU para procesar el modelo
▼
┌──────────────────────────────────────────────────────────────────────┐
│ ⚙️ NVIDIA Container Toolkit + Drivers CUDA │
│──────────────────────────────────────────────────────────────────────│
│ - “Puentea” la GPU física hacia los contenedores │
│ - Permite ejecutar CUDA/Tensor ops dentro de Docker │
│ - Asegura compatibilidad entre driver y librerías del contenedor │
└───────────────┬──────────────────────────────────────────────────────┘
│ 4️⃣ Acceso a la GPU física
▼
┌──────────────────────────────────────────────────────────────────────┐
│ 💻 GPU Física (RTX, CUDA cores, VRAM) │
│──────────────────────────────────────────────────────────────────────│
│ - Ejecuta el modelo LLM en paralelo masivo │
│ - Usa librerías CUDA/cuDNN/TensorRT instaladas en Ubuntu │
│ - Devuelve resultados procesados a Ollama │
└──────────────────────────────────────────────────────────────────────┘RAG
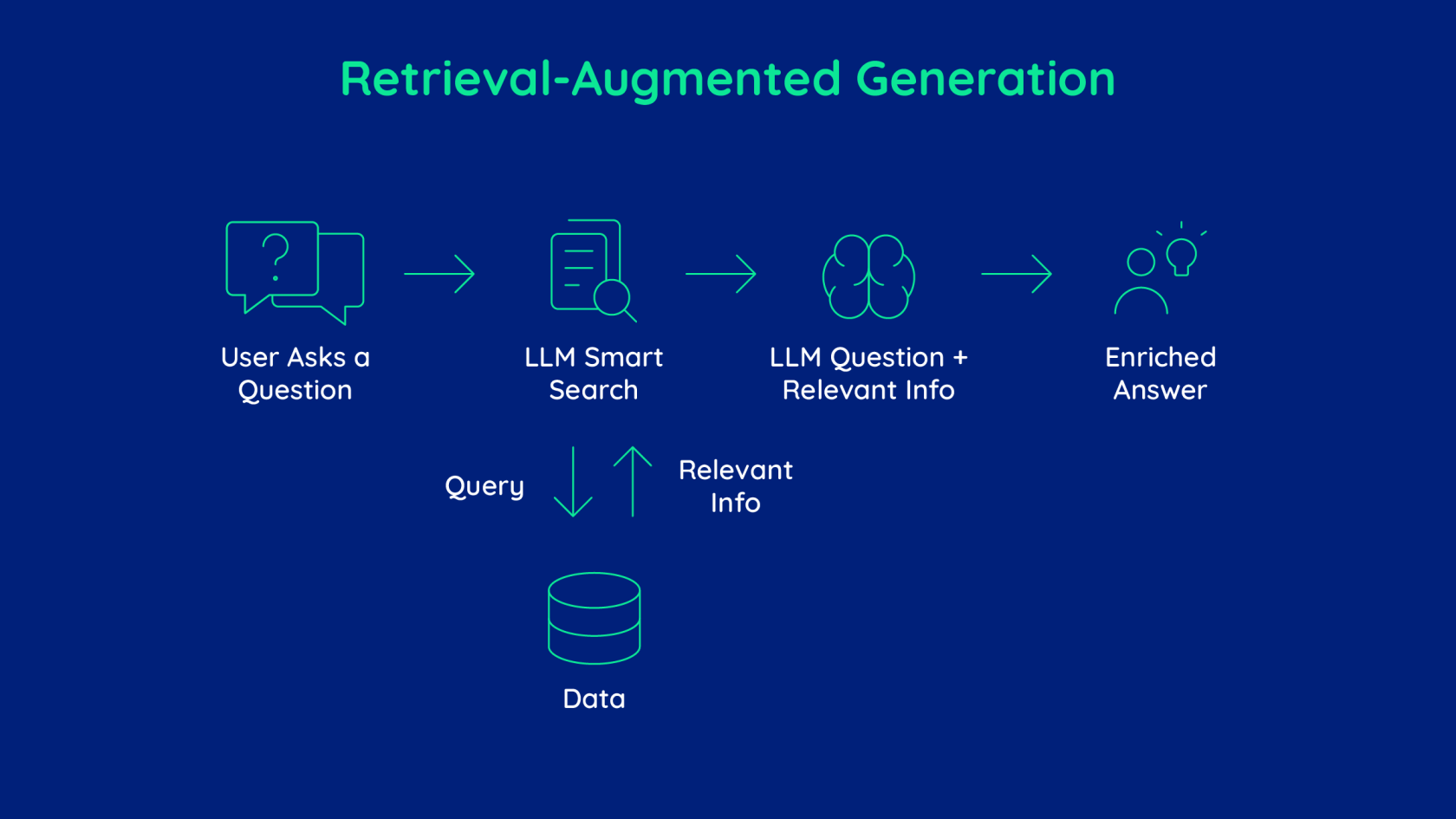
RAG viene de Retrieval-Augmented Generation,
que en español se traduce como “Generación aumentada con recuperación”.
💡 Es una técnica que combina un modelo de lenguaje (LLM) con una base de conocimiento externa (tus documentos, bases de datos, PDFs, etc.)
para que el modelo pueda responder con información real y actualizada, no solo con lo que aprendió en su entrenamiento.
Los modelos como Llama, GPT, Mistral, etc.:
-
No pueden aprender cosas nuevas después de ser entrenados.
-
No tienen acceso a tus documentos ni archivos locales.
-
Solo responden con lo que “saben” hasta su fecha de corte.
👉 Con RAG, puedes “alimentarlos” con conocimiento adicional sin reentrenarlos. Es como darle un superpoder de memoria externa.
Funcionamiento
Tu entorno tiene:
-
Ollama → ejecuta los modelos (Llama3.1, embeddings, etc.)
-
Open WebUI → interfaz para subir documentos y chatear
-
Qdrant → base vectorial (donde se guardan los embeddings)
Paso 1. Ingesta
Subes tus documentos (PDF, Word, Excel…). El sistema:
-
Lee el texto.
-
Lo divide en fragmentos (párrafos).
-
Convierte cada fragmento en un embedding (vector numérico).
-
Guarda esos vectores en Qdrant.
Paso 2. Recuperación (Retrieval)
Cuando haces una pregunta (por ejemplo:
“¿Cuáles son las políticas de privacidad del documento?”)
🔹 El sistema convierte tu pregunta en un embedding y busca los fragmentos más parecidos en la base vectorial.
(Esta es la parte de Retrieval — “recuperar información”).
Paso 3. Generación (Augmented Generation)
Luego pasa esos fragmentos relevantes al modelo Llama 3.1, y este genera una respuesta usando ese contexto. Así el modelo responde algo como:
“El documento establece que los datos de usuarios se almacenan durante 12 meses…”
👉 Esa información no estaba en el modelo originalmente, sino que fue “inyectada” dinámicamente desde tus documentos.
Resumen
| Etapa | Qué hace | Herramienta en tu stack |
|---|---|---|
| 1. Ingesta | Extrae texto y genera embeddings | Open WebUI + Ollama |
| 2. Recuperación | Busca fragmentos similares | Qdrant |
| 3. Generación | Crea la respuesta usando esos fragmentos | Llama 3.1 (via Ollama) |
Ventajas
✅ No necesitas reentrenar el modelo.
✅ Puedes actualizar el conocimiento simplemente subiendo nuevos archivos.
✅ Funciona offline (si todo está local).
✅ Mantiene privacidad total de tus datos.
✅ Se integra fácilmente con Open WebUI y Ollama.
Ejemplo real
Imagina que tienes un PDF con políticas internas de tu empresa.
❓ Pregunta al modelo:
“¿Cuál es la política sobre el uso de dispositivos personales?”
Sin RAG → El modelo te daría una respuesta genérica.
Con RAG → Buscará en el PDF, encontrará la sección exacta y responderá con detalle real.